공간 음향과 3D 사운드 디자인: 면을 뚫고 나오는 압도적 몰입감의 기술

왜 같은 장면인데 어떤 사운드는 머릿속까지 파고들까?
같은 영화 장면, 같은 게임 컷신을 봤는데도 어떤 사운드는 화면 안에 갇혀 있고, 어떤 사운드는 방 전체를 휘감아 등 뒤에서 속삭이는 느낌을 받은 적이 있습니까? 같은 헤드폰을 끼고 같은 영상을 봤는데, 한쪽은 평평한 벽처럼 들리고 다른 한쪽은 머리 바깥 3차원 공간에서 울리는 것처럼 들립니다. 이 차이는 헤드폰 가격이나 비트레이트만으로는 설명되지 않습니다.
많은 사운드 디자이너, 게임 오디오 프로그래머, 영상 크리에이터가 바로 이 지점에서 막힙니다. "공간 음향을 적용했다"고 적어놓고 막상 들어보면 스테레오 폭만 조금 넓어진 수준에 그치는 경우가 흔합니다. 객체 기반(Object-based) 믹스, 앰비소닉(Ambisonics), 바이노럴(Binaural) 렌더링 같은 용어가 뒤섞이면서 무엇을 언제 써야 할지 판단 기준조차 흐려집니다.
이 글은 "공간음향을 적용했다"는 한 줄을 자신 있게 쓸 수 있는 판단 기준을 제공합니다. 인간이 방향과 거리를 인식하는 원리, 핵심 기술 축의 선택 기준, 그리고 실제 워크플로우에서 무너지기 쉬운 지점을 짚어 정위·거리감·외재화 세 축으로 자신의 믹스를 재단할 수 있게 합니다.
공간 음향은 정확히 무엇이 다른가: 모노·스테레오·서라운드와의 결정적 차이
듣는다는 것의 메커니즘: ITD, ILD, 귓바퀴의 반사
인간이 눈을 감고도 소리의 방향을 짚어낼 수 있는 이유는 귀가 두 개이기 때문입니다. 정확히 말하자면, 두 귀에 도달하는 소리의 미세한 차이를 뇌가 해석하기 때문입니다. 이 차이는 크게 두 가지로 나뉩니다. ITD(Interaural Time Difference, 양이간 시간차) 는 왼쪽 귀와 오른쪽 귀에 소리가 도달하는 시각의 차이입니다. 오른쪽에서 박수를 치면 오른쪽 귀에 먼저 닿고, 머리를 돌아 왼쪽 귀에 약 0.6밀리초(약 600마이크로초) 늦게 도달합니다. ILD(Interaural Level Difference, 양이간 음량차) 는 머리가 음파를 가려 발생하는 음량 차이를 뜻합니다. 파장이 짧은 고주파일수록 머리에 의해 차단되는 정도가 큽니다.
여기에 더해 귓바퀴(Pinna)의 굴곡과 어깨 반사가 소리에 미세한 주파수 음영을 새깁니다. 같은 소리라도 위에서 오는지 아래에서 오는지에 따라 귓바퀴를 지나며 다른 주파수 응답을 만들고, 뇌는 이 패턴을 학습된 데이터베이스와 비교해 위치를 추정합니다. 이것이 바로 HRTF의 원리입니다.
평범한 스테레오 믹스가 좌우 폭만 줄 뿐 앞뒤·위아래의 입체감을 만들지 못하는 이유가 여기 있습니다. 좌우 패닝(panning)은 ILD만 흉내 낼 뿐 ITD나 귓바퀴 반사를 재현하지 않습니다. 그래서 헤드폰에서 들으면 소리가 '머리 안쪽'에서 울리는 두내정위(in-head localization) 현상이 발생합니다. 공간 음향이 노리는 가장 큰 효과는 바로 이 소리를 머리 바깥으로 밀어내는 외재화(externalization) 입니다.
💡 실전 팁: 자신이 만든 믹스가 '머리 안에 갇혔는지' 빠르게 주관 점검할 때는 눈을 감고 손가락으로 소리가 들리는 위치를 가리켜 보세요. 손가락이 귀 안쪽을 가리키면 외재화가 약한 신호이고, 머리 바깥의 한 점을 안정적으로 가리킬 수 있으면 외재화가 살아 있다는 신호입니다. 단, 외재화는 HRTF 적합도와 헤드폰 보정의 영향을 크게 받으므로 가능하면 여러 청취자, 여러 헤드폰에서 반복 점검하는 편이 좋습니다.
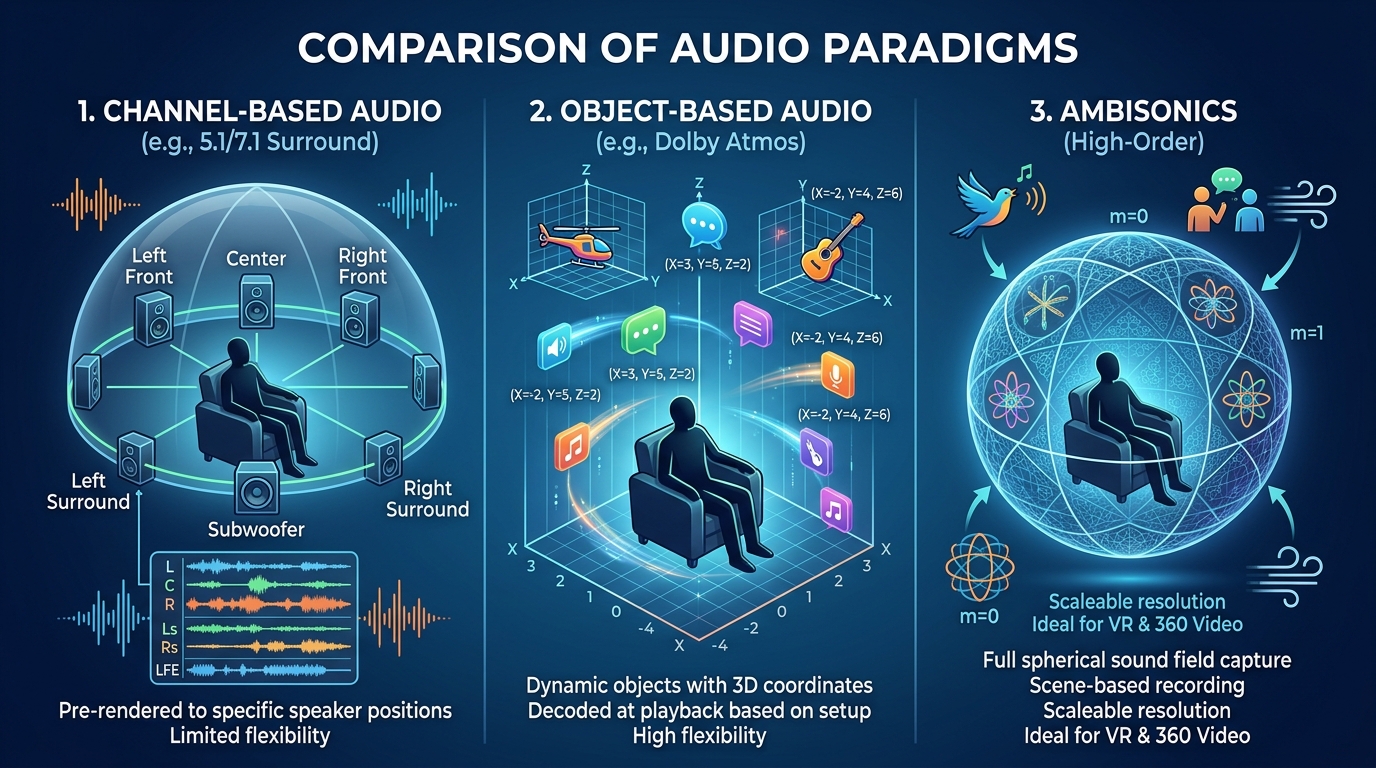
채널 기반, 객체 기반, 씬 기반: 세 가지 패러다임 비교
공간 음향을 다룰 때 가장 흔한 오해 중 하나가 "스피커 수가 많으면 공간 음향이다"라는 생각입니다. 5.1, 7.1 같은 전통적 서라운드는 채널 기반(Channel-based) 시스템에 속합니다. 사운드 디자이너가 각 스피커 채널에 직접 신호를 할당하고, 청취자의 재생 환경도 그 채널 수와 배치를 따라야 합니다. 의도된 채널 배치와 실제 재생 환경이 어긋날수록 정위와 밸런스가 달라집니다.
반면 객체 기반(Object-based) 시스템은 사운드를 '오디오 객체 + 메타데이터'로 다룹니다. "이 발자국은 3차원 좌표 (x, y, z)에 있다"는 정보를 함께 저장해 두면, 재생 단계에서 Dolby Atmos 디코더나 게임 엔진이 청취자의 스피커·헤드폰 구성에 맞춰 실시간으로 렌더링합니다. 같은 마스터가 7.1.4 시네마에서도, 사운드바에서도, 헤드폰에서도 의도에 가깝게 재생되는 이유입니다. Dolby Atmos와 DTS:X가 이 방식의 대표 구현입니다.
씬 기반(Scene-based) 은 음장(soundfield) 전체를 구면 조화 함수로 인코딩하는 방식이며, Ambisonics가 여기에 해당합니다. 1차 Ambisonics(B-format)는 W, X, Y, Z 네 채널로 전 방위 음장을 표현합니다. 가장 큰 장점은 회전입니다. 청취자가 VR 헤드셋에서 고개를 돌리면 음장을 그대로 회전시키기만 하면 되므로, 360 영상이나 VR 환경에 적합합니다.
몰입감을 결정하는 3대 요소: 정위, 거리감, 외재화
공간 음향의 품질을 평가할 때 흔히 "넓다", "둘러싼다" 같은 모호한 표현을 쓰지만, 실제로는 세 가지 측정 가능한 요소로 분해됩니다. 첫째는 정위(localization) 입니다. 소리가 어느 방향에서 오는지 짚어낼 수 있어야 합니다. 게임이라면 위협 방향 같은 핵심 단서음이 전·후·좌·우·상·하 같은 의도한 방향군 안에서 안정적으로 구분되는지가 기준입니다.
둘째는 거리감(distance) 입니다. 같은 발자국이라도 1미터 앞에서 나는지, 20미터 떨어진 복도 끝에서 나는지 구분할 수 있어야 합니다. 거리감은 단순히 음량을 줄이는 것만으로 만들어지지 않습니다. 직접음과 반사음의 비율(D/R ratio), 고주파 감쇠, 초기 반사(early reflections)의 패턴이 함께 작동해야 뇌가 거리를 추정합니다.
셋째는 앞서 언급한 외재화 입니다. 헤드폰에서 듣는 소리가 머리 바깥 공간에 존재하는 것처럼 느껴지는 정도를 가리킵니다. 외재화가 약하면 정위가 정확해도 몰입감이 깨집니다. 게임에서 적이 "왼쪽 귀 안쪽에" 있는 것처럼 들리면 위치 정보가 있어도 직관적으로 반응하기 어렵습니다.
자주 마주치는 함정은 이 셋을 하나로 묶어 평가하는 것입니다. "공간감이 부족하다"는 피드백이 왔을 때 정위가 약한 건지, 거리감이 평탄한 건지, 외재화가 무너진 건지 구분하지 못하면 엉뚱한 곳을 손보게 됩니다.
💡 실전 팁: 믹스 검토 시 체크리스트를 세 칸으로 나누세요. 첫 칸은 정위(방향 정확도), 둘째 칸은 거리감(가까움/멀어짐), 셋째 칸은 외재화(머리 바깥에 있는가). 한 장면을 들으며 세 칸을 각각 1~5점으로 평가하면 어디를 손봐야 할지 명확해집니다.
바이노럴·앰비소닉·HRTF: 엔지니어가 꼭 구분해야 할 3가지 기술 축
바이노럴: 두 귀로 듣는 그대로를 캡처하고 재현하기
바이노럴은 가장 직관적인 공간 음향 기술입니다. 대표적으로 Neumann KU 100은 사람의 머리와 상반신 구조를 정밀하게 재현한 더미 헤드 마이크이고, 3Dio Free Space는 머리 형태 모형 없이 실리콘 귀 모형을 양 끝에 배치한 형태의 바이노럴 마이크입니다. 두 방식 모두 두 채널이지만, 단순한 스테레오와 달리 ITD·ILD·귓바퀴 반사 정보가 함께 담깁니다. 헤드폰으로 재생하면 마치 그 장소에 직접 서 있는 듯한 외재화 효과를 얻습니다.
바이노럴 기술은 귀 가까이에서 속삭이는 소리, 등 뒤에서 다가오는 발걸음처럼 일반 스테레오로는 흉내 낼 수 없는 표현을 가능하게 합니다. 그래서 ASMR 콘텐츠 제작이나 VR 영상·360 다큐멘터리에서 분위기 구축의 핵심 도구로 자리 잡았습니다.
다만 한계도 명확합니다. 첫째, 헤드폰 재생을 전제로 합니다. 스피커로 재생하면 좌우 채널이 양쪽 귀에 모두 도달하는 크로스토크(crosstalk) 때문에 효과가 무너집니다. 둘째, 더미 헤드의 귓바퀴 모양이 청취자 본인의 귀와 다르면 정위 정확도가 떨어집니다. 셋째, 한 번 녹음하면 음장을 회전시키거나 객체 단위로 다시 믹스하기 어렵습니다. 그래서 바이노럴은 '캡처된 공간 음향'에 가깝고, 인터랙티브 환경보다는 선형 콘텐츠에 더 적합합니다.
💡 실전 팁: 바이노럴 녹음이 어렵다면 모노 소스에 바이노럴 패닝 플러그인(Dear Reality dearVR, IEM Plug-in Suite 등)을 적용해 비슷한 효과를 낼 수 있습니다. 단, 이 경우 적용되는 HRTF가 청취자에게 맞지 않으면 정위가 모호해질 수 있다는 점을 기억하세요.
앰비소닉: 회전 가능한 구면 음장
앰비소닉은 음장을 채널이 아닌 '구(sphere)' 단위로 다룬다는 점이 결정적 차이입니다. 1차 앰비소닉(First-Order Ambisonics, FOA)은 W(전방향 압력), X(전후), Y(좌우), Z(상하) 네 채널로 전 방위 음장을 인코딩합니다. 고차 앰비소닉(Higher-Order Ambisonics, HOA)으로 갈수록 해상도가 높아지며, 채널 수는 (N+1)²로 늘어나 3차 HOA는 16채널을 사용합니다.
가장 큰 강점은 회전성 입니다. VR 헤드셋에서 사용자가 고개를 왼쪽으로 90도 돌리면, 앰비소닉 음장 전체를 반대 방향으로 90도 회전시키는 행렬 연산만 적용하면 됩니다. 객체 기반에서 모든 객체 좌표를 재계산하는 것보다 훨씬 가볍게 처리됩니다. YouTube의 360 영상이 1차 앰비소닉(AmbiX 포맷, ACN/SN3D)을 지원하는 이유도 이 회전 효율성 때문입니다.
반면 한계는 해상도에 있습니다. 1차 앰비소닉은 정위 해상도가 거칠어 "왼쪽 어딘가"는 표현해도 좁은 각도까지 또렷이 짚어내기는 어렵습니다. 게임 같은 인터랙티브 환경에서 적의 정확한 위치를 알려야 한다면 객체 기반과 병행하는 편이 일반적입니다. 또한 앰비소닉 자체는 재생 포맷이 아니라 중간 표현이므로, 최종적으로는 바이노럴 디코딩이나 스피커 어레이 디코딩 과정을 거쳐야 합니다. 실무에서는 IEM Plug-in Suite의 BinauralDecoder, Reaper용 ambix 플러그인 패키지, 또는 게임 엔진의 앰비소닉 디코더 모듈이 자주 쓰입니다.

HRTF: 외재화의 비밀과 개인화 흐름
HRTF는 특정 방향에서 온 소리가 귓바퀴와 머리, 어깨를 거쳐 고막에 도달하기까지의 주파수 응답을 함수로 표현한 것입니다. 모든 방향에 대해 HRTF를 측정해 두면, 임의의 모노 소스에 해당 방향의 HRTF를 컨볼루션(convolution)해서 그 방향에서 들리는 것처럼 만들 수 있습니다. 이것이 바이노럴 렌더링의 수학적 기반입니다.
문제는 HRTF가 사람마다 다르다는 점입니다. 귓바퀴 모양, 머리 크기, 어깨 너비가 모두 영향을 미칩니다. 평균 HRTF로 만든 바이노럴 렌더링이 어떤 사람에게는 외재화가 강하게 느껴지고, 어떤 사람에게는 머리 안쪽에 갇힌 듯 들리는 이유입니다. 특히 앞뒤 혼동(front-back confusion), 즉 정면에서 오는 소리를 뒤에서 오는 것으로 착각하는 현상이 일반 HRTF에서 자주 발생합니다.
이 한계를 극복하기 위해 개인화 HRTF 가 상용 제품에 들어오기 시작했습니다. Apple은 iOS 16부터 TrueDepth 카메라로 얼굴과 귀 모양을 촬영해 개인화된 공간 음향 프로파일을 생성하는 기능을 제공합니다. Sony 360 Reality Audio도 헤드폰 전용 앱에서 양쪽 귀 사진을 캡처해 HRTF를 최적화합니다. 게임·VR 분야에서는 Steam Audio가 표준 규격인 SOFA(Spatially Oriented Format for Acoustics) 파일을 통해 사용자 정의 HRTF를 직접 로드할 수 있도록 지원합니다. 반면 Meta XR Audio SDK(과거 Oculus Audio SDK 계열)는 공개적으로 확인되는 범위에서 Steam Audio처럼 사용자 SOFA 파일을 직접 로드하는 워크플로우가 확인되지 않으며, 범용/고정 HRTF 기반 렌더링을 사용합니다.
💡 실전 팁: 자신의 콘텐츠를 바이노럴로 렌더링할 때 한 가지 HRTF로만 검증하지 마세요. 최소 2~3개의 대표 HRTF 데이터셋(예: MIT KEMAR, IRCAM Listen, CIPIC)을 번갈아 적용해 앞뒤 혼동이 어디서 더 잘 발생하는지 확인하면 더 견고한 믹스를 만들 수 있습니다.
기술 선택 기준을 한 줄로 요약하면 이렇습니다. 캡처된 실제 공간을 헤드폰으로 그대로 재현하고 싶다면 바이노럴 녹음, 회전 가능한 360 음장이 필요하면 앰비소닉, 인터랙티브하게 객체 단위로 위치를 조작하고 싶으면 객체 기반 + HRTF 렌더링을 사용하는 식입니다. 실제 프로젝트에서는 이 셋을 섞어 씁니다.
VR·AAA 게임·영상에서 실제로 어떻게 쓰이는가: 제작 워크플로우와 사례
게임 엔진 통합: Wwise, FMOD, Steam Audio의 역할 분담
게임에서 공간 음향이 작동하려면 두 가지가 맞물려야 합니다. 하나는 사운드 디자이너가 만드는 자산(소스 사운드, 어트리뷰트)이고, 다른 하나는 런타임에 그 자산을 청취자 위치와 환경에 맞춰 렌더링하는 엔진입니다. 이 런타임 처리를 담당하는 미들웨어가 Audiokinetic Wwise와 FMOD Studio입니다. 두 도구 모두 3D 패닝, 거리 감쇠, 도플러, 환경 리버브 같은 기본 공간 처리 기능을 제공하며, 플랫폼·플러그인·렌더러 구성에 따라 Dolby Atmos 계열 워크플로우와도 연동할 수 있습니다.
여기에 더 정교한 물리 기반 처리를 얹고 싶을 때 Valve의 Steam Audio나 Meta XR Audio SDK 같은 전용 스페이셜라이저를 결합합니다. Steam Audio는 씬의 지오메트리를 분석해 오클루전(소리가 벽에 막히는 현상), 트랜스미션(벽을 투과한 약화), 리얼타임 리버브를 광선 추적(ray tracing)에 가까운 방식으로 시뮬레이션합니다. 단순히 "이 방의 리버브 프리셋"을 적용하는 것과는 다른 접근입니다.
Unreal Engine 5는 MetaSounds라는 절차적 사운드 그래프 시스템과 함께 빌트인 공간화를 강화했고, Unity는 Audio Spatializer SDK를 통해 서드파티 스페이셜라이저를 플러그인 형태로 통합합니다. 어떤 엔진을 쓰든 핵심은 동일합니다. 음원에 3D 위치 메타데이터를 부여하고, 청취자(보통 카메라 또는 캐릭터의 머리)를 기준으로 매 프레임 렌더링한다는 점입니다.
공개된 사례 중 자주 인용되는 것이 Ninja Theory의 'Hellblade: Senua's Sacrifice'입니다. 주인공의 환청을 표현하기 위해 바이노럴 렌더링(3Dio 기반)을 핵심 오디오 파이프라인으로 채택해, 헤드폰 착용 시 목소리가 머리 주변을 회전하며 속삭이는 듯한 효과를 구현했습니다. 이외에도 다수의 AAA 잠입·액션 게임이 발자국과 환경음의 위치 단서를 강화하기 위해 3D 포지셔닝과 환경 처리를 적극적으로 활용해 왔습니다.

영상과 VR: Atmos 음악부터 Vision Pro까지
영상 쪽에서 공간 음향의 진입 경로는 두 갈래로 나뉩니다. 하나는 영화·드라마의 시네마틱 믹스, 다른 하나는 360 영상·VR 콘텐츠입니다. 시네마틱 쪽에서는 Dolby Atmos가 사실상 표준에 가깝습니다. Avid Pro Tools와 Dolby Atmos Renderer를 연동하면 트랙별로 객체 또는 베드(bed) 채널을 지정하고, 7.1.4(평면 7채널 + LFE 1채널 + 천장 4채널) 모니터링 환경에서 믹스한 뒤 Atmos 마스터(ADM BWF 파일)로 내보냅니다. 같은 마스터가 사운드바, AV 리시버, 헤드폰에서 자동으로 다운믹스 또는 바이노럴 렌더링됩니다.
음악에서도 Atmos 적용이 확대됐습니다. Apple Music과 Amazon Music이 Dolby Atmos 카탈로그를 제공하며, 지원 기기와 설정을 갖춘 경우 일부 이어폰·헤드폰의 동적 헤드 트래킹과 결합된 공간 오디오로 들을 수 있습니다. 다만 음악 Atmos 믹스는 영상과 달리 "관객을 둘러싸는" 미학이 작품성과 직결되므로 호불호가 갈리는 영역이기도 합니다.
VR과 360 영상 제작에서는 한때 널리 쓰인 도구 중 하나로 Facebook(현 Meta)의 Spatial Workstation이 있었고, 이후 Google Resonance Audio, YouTube의 1차 앰비소닉 + 헤드 락 스테레오 조합 등 여러 워크플로우가 병존해 왔습니다. Apple Vision Pro가 등장하면서 공간 비디오와 공간 오디오를 한 묶음으로 다루는 파이프라인이 강조됐고, AirPods Pro 등에서 제공되는 헤드 트래킹 기반 공간 오디오와 결합해 영상 콘텐츠 제작자에게 새로운 검증 환경이 생겼습니다.
💡 실전 팁: Atmos 믹스를 검토할 때는 항상 다운믹스 호환성을 확인하세요. 사용자 다수가 결국 스테레오, TV 스피커, 사운드바, 일반 헤드폰 등 다양한 환경에서 듣게 됩니다. Renderer에서 "Re-render to 2.0"으로 변환한 결과가 위상 문제나 보컬 매몰 없이 들리는지 점검해야 마스터로 인정할 수 있습니다.
단계별 제작 워크플로우와 유의할 지점
공간 음향 제작은 대체로 네 단계로 정리할 수 있습니다.
1단계, 소스 녹음 또는 합성. 정확한 단일 객체 정위가 필요한 소리는 모노 소스가 안전합니다. 반면 배경 앰비언스나 넓은 환경음은 스테레오 또는 앰비소닉 소스를 목적에 맞게 별도 처리하는 편이 더 풍부한 공간감을 만들기도 합니다. 단, 이미 스테레오로 인코딩된 소스를 바이노럴 패너에 통과시키면 위상 충돌로 정위가 흐려질 수 있으므로, 패너 중복 적용과 모노 합산 후 위상 점검을 함께 진행해야 합니다. 환경음 전용 녹음에는 Sennheiser AMBEO VR Mic, RØDE NT-SF1 같은 앰비소닉 마이크나 임펄스 응답 활용이 자주 쓰입니다.
2단계, 공간 메타데이터 부여. 게임이라면 엔진의 3D 위치 좌표, 영상이라면 Atmos 객체 좌표 또는 앰비소닉 인코더의 방향 값을 설정합니다. 이 단계에서 자주 보이는 문제는 좌표를 너무 자주, 너무 크게 움직이는 것입니다. 청취자의 뇌가 따라가지 못하면 위치 정보가 의미를 잃고 피로감만 남습니다. 또한 한 장면 안에서 가장 중요한 한두 개 소스(주인공의 발자국, 적의 위협음 등)에 정위 우선순위를 두고 나머지는 약간 흐릿하게 두는 편이 좋습니다. 모든 소리를 똑같이 또렷하게 정위시키려 하면 청취자의 주의가 분산되어 오히려 몰입이 깨지기 때문입니다.
3단계, 렌더링과 모니터링. 바이노럴 렌더링, 스피커 어레이 렌더링, Atmos 객체 렌더링 등 타깃에 맞춰 변환합니다. 이때 반드시 재생 환경별로 교차 검증 해야 합니다. 7.1.4 스튜디오에서 완벽했던 믹스가 헤드폰에서 무너지는 경우가 많기 때문입니다.
4단계, 호환성 검증. 헤드폰, 사운드바, TV 스피커, 블루투스 이어폰까지 대표 디바이스에서 들어봅니다. 특히 모노 호환성은 자주 잊히는 부분입니다. 객체 기반 믹스에서 두 객체가 좌우 대칭으로 위치하면 모노 다운믹스 시 위상 상쇄로 음량이 줄어들 수 있습니다.
제작 중 자주 발생하는 오류를 짚어 봅니다. 첫째, 과도한 리버브 입니다. 거리감을 주려고 리버브를 과하게 걸면 외재화는 강해질지 몰라도 정위가 무너집니다. 둘째, 위상 문제 입니다. 바이노럴 패너에서 같은 모노 소스를 두 군데서 동시에 재생하면 미세한 지연 차이로 콤 필터(comb filtering)가 발생합니다. 셋째, 모니터링 환경 불일치 입니다. 한 가지 헤드폰으로만 검증하면 그 헤드폰의 주파수 응답에 맞춰 믹스가 편향됩니다.
몰입감을 깨뜨리는 함정과 즉시 적용 가능한 체크리스트
믹스 단계의 함정: 위상, EQ, LFE, 모니터링
공간 음향 믹스가 무너지는 첫 번째 원인은 거의 항상 위상입니다. 같은 신호를 두 채널에 미세한 시간차로 보내면 특정 주파수가 강조되거나 사라지는 콤 필터 효과가 생깁니다. 바이노럴 패너에서 의도적으로 만들어진 ITD라면 문제없지만, 의도하지 않은 지연이 끼어들면 정위가 모호해지고 외재화도 약해집니다. 점검 단계에서 모든 트랙을 모노로 합산했을 때 음량이 급격히 떨어지는 구간이 있다면 위상 문제를 의심해야 합니다.
EQ도 자주 발목을 잡습니다. 공간 음향에서 HRTF는 본질적으로 주파수 영역의 패턴 함수이기 때문에, 고주파(특히 4~10kHz)를 무리하게 깎으면 귓바퀴 큐가 사라져 위아래 정위가 무너집니다. 반대로 저역(80Hz 이하)에 과도한 부스트를 주면 헤드폰에서 머리 진동처럼 느껴져 외재화가 깨집니다. 공간 음향용 EQ는 평소보다 좁고 보수적으로 다루는 편이 안전합니다.
LFE(저주파 효과) 채널은 별도의 주의가 필요합니다. 객체 기반 믹스에서 위치 단서가 필요한 저역은 해당 객체나 메인 채널에 포함시키고, LFE는 전용 저주파 효과가 필요한 경우에 제한적으로 사용하는 편이 호환성이 좋습니다. LFE는 위치 정보가 없는 채널이기 때문입니다.
마지막은 모니터링 환경입니다. 한 헤드폰으로만 점검하면 그 헤드폰의 주파수 응답에 묶이고, 스피커 환경에서만 점검하면 헤드폰 사용자의 경험을 놓칩니다. 최소한 개방형 헤드폰 한 개, 밀폐형 한 개, 가능한 경우 7.1.4 스피커 환경을 교차로 사용해야 합니다.
💡 실전 팁: 믹스 점검의 마지막 단계로 "안 좋은 환경" 테스트를 추가하세요. 노트북 내장 스피커, 저가 블루투스 이어폰처럼 일반 사용자가 실제로 듣는 환경에서 정위와 명료도가 어디까지 살아남는지 확인하면 마스터의 견고함을 판단할 수 있습니다.
디바이스·플랫폼 호환성: '가짜 공간 음향'을 피하는 법
스트리밍 서비스의 '공간 음향' 라벨이 모두 같은 품질을 보장하지는 않습니다. 일부 콘텐츠는 진짜 객체 기반 Atmos 마스터에서 시작했지만, 일부는 스테레오 마스터에 후처리로 업믹스만 적용한 경우도 존재합니다. 업믹스 기반은 정위가 모호하고 외재화도 평탄하므로, 제작자 입장에서는 자신의 마스터가 어느 경로로 유통되는지 확인하는 것이 중요합니다.
모바일과 블루투스 환경도 변수가 큽니다. 블루투스 오디오 코덱은 SBC, AAC, aptX, aptX HD, LDAC 등이 있으며, 각각 최대 비트레이트와 지연 특성이 다릅니다. 일부 코덱은 좌우 채널의 시간 동기화 정확도가 낮아 ITD 기반 정위가 흔들릴 수 있습니다. 헤드 트래킹 기반 공간 오디오는 일반적으로 수십 밀리초 수준의 end-to-end latency를 넘어서면 콘텐츠와 회전 속도에 따라 머리 회전과 음장 회전이 어긋나 부자연스럽게 느껴질 수 있다고 알려져 있습니다. 그래서 헤드 트래킹 환경에서는 전체 지연을 별도로 측정해 두는 편이 안전합니다.
플랫폼별 디코딩 차이도 점검해야 합니다. Dolby Atmos for Headphones, Windows Sonic, DTS Headphone:X, Apple Spatial Audio는 모두 비슷한 목적을 가지지만 내부 HRTF와 렌더링 알고리즘이 다릅니다. 같은 마스터가 플랫폼별로 다르게 들립니다. 게임이라면 사용자가 활성화한 OS 레벨 공간화와 게임 내부 스페이셜라이저가 이중으로 적용되어 정위가 오히려 흐려지는 경우도 있습니다.
💡 실전 팁: 플랫폼 호환성 문서를 한 페이지로 만들어 두세요. "이 마스터는 Dolby Atmos Renderer 기준이며, AirPods Pro의 Personalized Spatial Audio에서는 약간 더 가까운 거리감으로 들립니다" 같은 메모를 기록해 두면 외부 피드백을 받을 때 혼선을 줄일 수 있습니다.
실전 체크리스트: 초보와 숙련자의 차이
같은 도구로 작업해도 초보와 숙련자의 결과물 차이는 체크리스트의 깊이에서 갈립니다. 초보는 "공간 음향 플러그인을 켰는가"에서 점검을 멈추지만, 숙련자는 다음 항목을 모두 거칩니다.
소스 단계
단일 정위가 필요한 소리는 모노 소스로 정리되어 있는가
샘플레이트와 비트 뎁스가 마스터 체인 전체에서 일관되는가
노이즈 플로어가 외재화 효과를 가리지 않는가
중요한 단서음이 의도한 방향군(전·후·좌·우·상·하) 안에서 안정적으로 구분되는가
거리감이 직접음/반사음 비율로 표현되었는가, 단순 음량 조절만 한 것은 아닌가
청취자 머리 회전 시 음장이 자연스럽게 따라오는가 (헤드 트래킹 환경)
헤드폰 2종 이상, 스피커 1종 이상에서 교차 검증했는가
모노 다운믹스에서 위상 상쇄로 사라지는 요소가 없는가
30분 이상 연속 청취 시 피로감이 누적되지 않는가
공간 처리 단계
검증 단계
Before/After 시나리오를 생각해 봅니다. 초보가 만든 VR 장면에서는 적이 뒤에서 다가올 때 발자국이 "왼쪽 어딘가"로만 들리고 정확한 위치는 알 수 없습니다. 숙련자가 같은 장면을 다시 믹스하면 발자국이 등 뒤 방향, 약 3미터 거리에서 들리며, 적이 가까워질수록 직접음 비율이 늘고 고주파 디테일이 살아납니다. 같은 자산을 썼지만 정위·거리감·외재화 세 축을 의식적으로 설계했는지에서 격차가 벌어집니다.
마지막으로 짚어 둘 한 가지는 청취자 피로도입니다. 공간 음향은 강하게 적용할수록 인상적이지만, 게임이나 영상이 한두 시간 이어진다면 과도한 효과는 피로를 누적시킵니다. 가장 중요한 순간에 공간 효과를 강하게 쓰고, 일상 장면에서는 절제하는 다이내믹 설계가 장시간 몰입을 유지하는 비결입니다.

화면 너머로 소리를 밀어내는 가장 빠른 길
공간 음향의 본질은 스피커 개수나 채널 수가 아니라 정위, 거리감, 외재화 세 축을 의식적으로 설계하는 일입니다. 바이노럴, 앰비소닉, HRTF는 각각 다른 문제를 풀기 위한 도구이며, 캡처·회전·인터랙티브 중 무엇이 필요한지에 따라 골라 쓰는 선택지입니다. 그리고 최종 몰입감은 워크플로우의 마지막 단계, 즉 다양한 재생 환경에서의 교차 검증이 결정합니다.
오늘 당장 시도해 볼 작은 행동을 하나 제안합니다. 현재 작업 중인 프로젝트에서 가장 중요한 한 장면을 골라 두 가지 버전을 만들어 보세요. 하나는 평소처럼 스테레오 패닝만 적용한 버전, 다른 하나는 바이노럴 패너 또는 객체 기반 스페이셜라이저로 같은 장면을 렌더링한 버전입니다. 헤드폰을 끼고 눈을 감은 채 두 버전을 번갈아 들으며 정위가 어디서 살아나는지, 외재화가 어디서 무너지는지 메모해 보세요. 단 한 장면의 A/B 비교만으로도 자신의 믹스가 손봐야 할 지점이 또렷하게 드러납니다.
소리는 공간을 만듭니다. 화면 안에 갇힌 사운드를 화면 바깥, 청취자의 방 안으로 밀어내는 작업은 거창한 장비보다 세 축에 대한 분명한 감각에서 시작합니다. 더 깊은 몰입을 설계하는 여정에 이 글이 단단한 출발점이 되기를 바랍니다.
